
My First Quantum Agent
I’ve gotten to a major milestone in this project. I’ve trained and tested my first quantum-trained AlphaZero agent! It appears to behave the way I was hoping it would.

Analysis of Adjudication of Terminal States for Small Graphs
I like the ‘fixed vertex’ variant of Tangled. I don’t think the freedom to choose your vertex adds anything to the game. So from now on, unless explicitly otherwise stated, all the results I’ll show are for the fixed token placement variant. In this post I adjudicate all unique terminal states for graphs 11, 2, 20, 3, and 19. Graph 19 (the barbell graph) is the smallest graph I’ve looked at where the hardware-based quantum annealing and simulated annealing results give different terminal state adjudication results — about 6% of the terminal states disagree on who won the game.

Modified Tangled With Fixed Token Positions
An idea I had was to modify Tangled to fix the token locations for the players, removing the freedom to choose where to place them. If we do this, then player actions are only edge coloring throughout the game, and intuitively it makes it more likely that action selections should matter throughout the game and not just at the end.

Some Thoughts on Quantum Mechanics and Consciousness
Today I wanted to veer slightly off-topic and write about two of my favorite topics… quantum mechanics and consciousness!
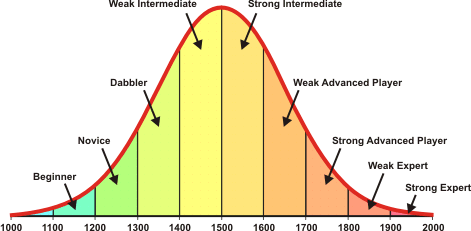
Setting up Elo Scores For a New Game
The Elo rating system is a method for calculating the relative skill levels of players in zero-sum games, such as chess and Go. It is named after its creator Arpad Elo, a Hungarian-American physics professor. Here I show how to implement it for a new game, and measure the Elo scores for some pure MCTS on different Tangled game graphs.

Snarks!
Today I would like to invite you to come falter with me down black cobwebbed steps to meet a thing only whispered about in the carven mausolea of university math departments: snark graphs. The term "snark graph" was coined by Martin Gardner in 1976, inspired by Lewis Carroll's poem The Hunting of the Snark.
Deconstructing AlphaZero Part 5: The Joys and Horrors of Parallelization
I spent a month trying to parallelize AlphaZero’s self-play and competitive phases. About three weeks in I was about to give up but I gave it one more go, and … success! Once I’d figured it all out, I got about 15-20x wallclock speedup on my 3090 + 10-core home setup.
This gives a blow-by-blow of how I got this over the finish line, with advice on how to structure python multiprocessing setups.

Deconstructing AlphaZero Part 4: How An Agent Learns
Here I want to show you how an AlphaZero agent learns about its world. As it learns, its ability to intuit what to do grows, and it gets better at taking actions that help in achieving its intrinsic goal.

Deconstructing AlphaZero Part 3: How You Gonna Act Like That
The defining feature of an agent is that it makes choices about what actions to take, given its current understanding of the world.
In this post, I describe how an AlphaZero agent makes the choices that it does. I also include some video describing part of what’s going on, which I decided to include as the inaugural episode of a new podcast. Exciting!

Deconstructing AlphaZero Part 2: State, Actions, and Reward, and Dreaming of Game Trees
There are three key things you need to define before you build any reinforcement learning agent — state, actions, and reward.
In this post I’ll guide you through how to do this, with a worked example for Tangled!

Deconstructing AlphaZero Part 1: Introduction
AlphaZero is a beautiful algorithm developed by the folks at DeepMind around 2016-2017. Its output is a software agent — an AI system that has agency (it makes decisions and takes actions by itself with no outside intervention).
In the next few posts, I’ll explain how AlphaZero works, and show how to use it to build superhuman agents for playing games.

A Fun Math Problem
In the set of all possible four vertex complete graphs with one red vertex, one blue vertex, and two black vertices, and each edge colored with one of three colors, how many unique graphs are there?
The image here is what Microsoft’s image generator spat out with a prompt of “Burnside’s lemma”.

Adjudicating Tangled Terminal States on Tiny Graphs With Three Different Approaches
I adjudicated all Tangled terminal states for both three- and four-vertex complete game board graphs using three different approaches — a numerical Schrodinger Equation solver, a specially tuned simulated annealing approach run on the s=1 Hamiltonian, and a D-Wave Advantage2.5 system using multiple embeddings. I found 100% agreement between all three for all terminal states for both graphs.

How I Adjudicate Tangled Terminal States Using D-Wave Hardware
D-Wave’s hardware is not easy to understand or use properly. I have trouble understanding how to get it to do what I want, and I have a PhD in physics and was the CTO of the company for more than a decade!
In this post, I want to show you what I did to get the system to do what I want.

Some Very Useful Tools
Thought I’d do a post with links to some tools I use. Some of this is specific to blogging using Squarespace, but some of it could be more generally useful!

Is it Possible to Build a One-Person Billion Dollar Company?
A few weeks ago I was at an event where one of the speakers was talking about how transformative generative AI is for start-ups. Not only could you use these new tools to build products, but likely you could also use them to reduce the number of people you need in a start-up. He claimed that it may now be possible to build a billion dollar start-up with only one person!

Parallelizing Computation Using D-Wave Processors Via Multiple Simultaneous Embeddings
If we want to use a processor to solve a problem that is much smaller than the size of the hardware graph, one cool technique we can use is to find multiple non-overlapping ways to fit our problem into the hardware graph. These ‘fits’ are called embeddings. If you can find a bunch, then each time you call the processor, you get all of them solved for you at once. Not only does this give you a pretty big speed up (up to about 200-350x faster for the problems I’ll show you here), but it gives a neat way to average over certain types of noise in a processor.

The Computational Cost of Using the Schrodinger Equation to Adjudicate Terminal States in Tangled
Evaluating who won a Tangled game requires solving the Schrodinger equation with N qubits, giving O(2ᴺ) scaling in both required memory and compute time.

Building Three Tangled Agents
A software agent is an artificial intelligence software program designed to take actions (ie have agency) in response to the state of their environment.
Let’s look at how to build game-playing agents for any Tangled game board. We can then play against these agents, and agents can play against each other!

Tangled on a 4-vertex graph
The three-vertex Tangled game board I introduced in the previous post is the smallest where one player can win (two vertex games always end in a tie). Let’s take a look at Tangled on a four-vertex six-edge graph. It's still stupidly small, but maybe we can learn something!