Influence
The last thing I’d like to talk about before introducing our first target game is a generalization of correlation which I call influence.

In models of magnetism, what I’m calling influence is called a spin-spin correlation function. You can call it that if you want. Yeah I know I shouldn’t be renaming things that already have perfectly good names. Sue me.
I’ll start by introducing the most abstract version of this. Let’s assume that we have a system of N two-state objects, like I introduced in the previous post, and furthermore let’s assume that we measure the state of the entire system M times.
This will give us M vectors of (+1,-1) variables of length N. For example, let’s say we had 3 quarters (so N=3), and we flip all three 5 times (so M=5). Then the results could be… hold on I’m flipping quarters in the real world… [1, -1, -1], [-1, -1, 1], [1, 1, 1], [-1, 1, 1], and [1, -1, -1], where +1 means heads and -1 means tails.
After we’ve collected this data, we can then calculate the correlation between all pairs of the three quarters using the simple formula I introduced earlier. If I do this with this data, I get C₀₁ = (-1+1+1-1-1)/5 = -0.2, C₀₂=(-1-1+1-1-1)/5 = -0.6, and C₁₂=(1-1+1+1+1)/5 = 0.6.

I now define the influence of each variable to be the sum over all the correlations of all the other variables to it. This assigns a number (influence) to each object; the influence of the kth object is:
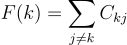
If we compute this for our three quarters we get: F(first quarter) = F(0) = C₀₁ + C₀₂ = -0.8; F(second quarter) = F(1) = C₀₁ + C₁₂ = 0.4; and F(third quarter) = F(2)= C₀₂ + C₁₂ = 0.
If we rank them by influence, we find that the second quarter has the most (F=0.4), the third quarter is next (F=0), and the first quarter has the least (F=-0.8).
Note that in this description, nowhere did I make any assumptions about the system, except that it contains N two-state objects. For example, I didn’t assume any particular probability distribution, or the nature of the interactions (or lack thereof) of the objects.
All of the correlation data, and then by extension the influence of each variable, is assumed to be measured from the real world and agnostic to any deeper explanation of why the measurements are the way they are.
An Example of Computing Influence in a Social Network
To start getting a feel for how influence works, let’s build a small social network! I’ll use four of my real-life friends (names changed to protect the innocent, but you know who you are :-) ) — Gary, Coco, Oprah, and Margaret. I’ll label them respectively 0, 1, 2, and 3. They each answered 30 binary ‘this/that’ questions. You can find the questions and answers here.

A remarkably non-accurate image of Gary, Oprah, Coco, and Margaret. I’ll leave it up to you to decide if that’s stud Gary or stupid Gary.
We can calculate the correlation between all of these answers — just add up all the places where two people agree, subtract the number where they don’t, and divide by 30 (the total number of questions). For example, when I calculate the correlation between Gary and Coco, I see agreement on 18 of the questions, and disagreement on 12, giving a correlation C(Gary, Coco) = C₀₁ = (18-12)/30 = 6/30 = 0.2. Positively correlated!! Yey Gary and Coco! I can likewise calculate all the other pairwise correlations, and get C₀₂=0.07, C₀₃=0.4, C₁₂=0.33, C₁₃=0.27, and C₂₃=0.53.
An interesting aside is that all these correlations are positive, which means everyone in my friend group generally agrees with everyone else on the answers to most of these questions. If we were to introduce another person very unlike my friend group, we’d probably see negative correlations between them and the other folks.
The Influence of Each Member of The Network
In our social network, each person’s influence is the sum over the correlations they have with the other three people: F(Gary) = F(0) = C₀₁ + C₀₂ + C₀₃ = 0.67. The other values are F(Coco) = F(1) = C₀₁ + C₁₂ + C₁₃ = 0.8, F(Oprah) = F(2) = C₀₂ + C₁₂ + C₂₃ = 0.93, and F(Margaret) = F(3) = C₀₃ + C₁₃ + C₂₃ = 1.2.
If we rank my four friends by influence, we get Margaret first, then Oprah, then Coco, and last Gary.
Is ‘Influence’ The Right Word For This?
This thing we just calculated is “who is more likely to agree most with the other members of the network over the question set provided”.
Is influence the right word for this? I’m actually not sure. None of my friends communicated about their answers, and it’s unlikely any of them felt ‘influenced’ by the others when answering. I guess the question is one of semantics — does influence imply you actually take actions to change people’s answers, or is it some other type of nebulous action-at-a-distance thing?
What if we added a 31st question, let’s say “Dark chocolate or milk chocolate?”, and we were to play the following game: you and I both pick a member of the network, and we add up the number of times the other three agree with them on the new question. If the majority give the same answer as your pick, you win, and if the majority give the same answer as my pick, I win. Just given the data above, who would you pick?
I want you to actually do this, pick one of the four people (Gary, Coco, Oprah, or Margaret), just based on the answers they gave to the first 30 questions.
Here’s the answers my friends gave to the dark vs milk chocolate question: [Gary: dark, Coco: dark, Oprah: milk, Margaret: dark]. For this new question, if you’d picked the obvious candidate (Margaret, who has the highest influence score on the previous 30 questions), you would have won the game, as 2/3rds of the others agreed with her! Of course just having one question introduces a lot of randomness, but you get the idea.
The objects in an N-object set with higher influence scores are more indicative of the ‘zeitgeist of the group’, and are more likely to tell you what the majority of the objects in the group would respond with when asked a new question of the same type.
Influence for the Ising Model
Given a probability distribution over states with energies given by an Ising model with N variables, computing influence is straightforward. We do this:
Perform M measurements of all N variables in the Ising model, just like we did with the coins example
Compute all pairwise correlations Cᵢⱼ between variables i and j from the data (there are N*(N-1)/2 of these correlations)
Compute the influence F(k) for all variables k=0..N-1
Step 1 is a sampling step where we have to actually measure things from the real world. Steps 2 and 3 are easy computation steps we do with a computer.
When we do Step 1, we are sampling from an underlying probability distribution. If the system is in thermal equilibrium at temperature T, this will be a Boltzmann distribution. If it isn’t, it could be anything!
Going back to our N=3 variable Ising model from the previous post, let’s say we make M=5 measurements of the system, assuming it’s in a Boltzmann distribution, each obtained by generating a random number between 0 and 1 and picking the corresponding state. I wrote a short piece of code to do this, and here’s the results:
random numbers = [0.88470, 0.03372, 0.31787, 0.20979, 0.91773]
The most likely state has probability 0.91646, so all of these except the last one return the most likely state, which is [-1,+1,-1]
The second most likely state has probability 0.05573, so the last sample 0.91773 < 0.91646 + 0.05573 and therefore returns the second most likely state, which is [+1,-1,+1]
So the M=5 states returned as samples are [ [-1,+1,-1], [-1,+1,-1], [-1,+1,-1], [-1,+1,-1], [+1,-1,+1] ]
The correlations from this data can then be computed; they are C₀₁ = (-1-1-1-1-1)/5 = -1; C₀₂ = (1+1+1+1+1)/5 = +1; C₁₂ = (-1-1-1-1-1)/5 = -1. The influence numbers are then F(0) = C₀₁+C₀₂=0; F(1) = C₀₁+C₁₂=-2; and F(2) = C₀₂+C₁₂=0.
If you stare at the samples you can see that the middle variable always disagrees with the other two every time — that’s why it’s influence is low. The first and third variables always agree with one of the others and disagree with one of the others; that’s why their influence is zero (but still higher that the middle guy!).